



Leetcode 146. LRU 缓存
Design and implement a data structure for Least Recently Used (LRU) cache. It should support the following operations: get and put.
get(key) - Get the value (will always be positive) of the key if the key exists in the cache, otherwise return -1. put(key, value) - Set or insert the value if the key is not already present. When the cache reached its capacity, it should invalidate the least recently used item before inserting a new item.
The cache is initialized with a positive capacity.
Could you do both operations in O(1) time complexity?
翻译:
设计并实现最近最少使用(Least Recently Used, LRU)缓存的数据结构。它应该支持以下操作:get和put。
get(key) -如果键存在于缓存中,则获取键的值(将始终为正),否则返回-1。put(key, value) -如果键不存在,设置或插入值。当缓存达到其容量时,它应该在插入新项之前使最近最少使用的项无效。
缓存初始化为正容量。
设计并实现最近最少使用(Least Recently Used, LRU)缓存的数据结构。它应该支持以下操作:get和put。
get(key) -如果键存在于缓存中,则获取键的值(将始终为正),否则返回-1。put(key, value) -如果键不存在,设置或插入值。当缓存达到其容量时,它应该在插入新项之前使最近最少使用的项无效。
缓存初始化为正容量。
你能在0(1)的时间复杂度内完成这两个操作吗?
相信很多同学面试的时候都遇到过这道题吧,尤其是某节,那么我们今天就来详细分析下这道算法题。
LRU(Least Recently Used)缓存机制是一种常用的数据缓存策略,它删除最长时间未被使用的数据项。这种策略的面试题不仅测试打工牛马对于数据结构(如哈希表和双向链表)的掌握,还考查其对于缓存机制、内存管理和算法优化的深入理解。面试这道题可以检验多方面的能力:
- 数据结构和算法:实现 LRU 缓存机制通常需要使用到复合数据结构,最常见的实现方式是结合使用哈希表和双向链表。这检验了候选人对数据结构的理解和应用能力。
- 系统设计:缓存是系统设计中常见的组件,关系到程序的性能和效率。通过这种问题,面试官可以评估候选人在系统架构和设计方面的能力。
- 性能优化:LRU 缓存涉及到性能优化,特别是在处理大量数据和高速缓存操作时的效率问题。
- 并发处理:在多线程环境中,如何保持 LRU 缓存的线程安全,是一个高级话题,考察候选人对并发编程的掌握。
咱就是说,当牛马容易吗?
Android 中的应用
LRU缓存在我们的实际开发中的应用并不少见,最典型的是在Android开发中,我们尝试用的两个第三方库:okhttp和glide,在 Android 开发中,LRU 缓存被广泛用于优化内存使用和提升应用性能。特别是在网络请求和图片加载库中,LRU 缓存能有效减少网络带宽的使用和提升用户界面的响应速度。下面是两个著名库中的应用实例:
- OkHttp:
- HTTP 缓存:OkHttp 使用 LRU 策略来缓存HTTP响应。这种缓存可以帮助减少重复的网络请求,加快页面加载速度,并且减少网络数据的使用。这对于移动设备尤为重要,因为它们通常依赖于有限的数据计划和不稳定的网络连接。
- 连接池管理:OkHttp 还使用类似 LRU 的策略管理和复用 HTTP/S 连接。保持连接的复用可以显著提高性能,因为创建新连接(尤其是加密连接)成本较高。
- Glide:
- 图片缓存:Glide 使用 LRU 缓存策略来存储图片和其他资源。这种缓存策略帮助减少内存使用,并提高图片加载的速度。Glide 对图片进行缩放和格式转换后,将其缓存起来,当再次请求同一图片时,可以直接从缓存中加载,避免重复的处理和下载。
- 内存管理:为了防止应用消耗过多内存而被系统杀死,Glide 使用一个基于 LRU 策略的内存缓存来优先移除最近最少使用的图片资源。
通过这些应用,LRU 缓存帮助 Android 应用在维持低内存使用的同时,还能保持良好的用户体验和应用响应速度。这是为什么很多 Android 库和应用都选择实现和优化 LRU 缓存策略的原因。
Java 后端开发中实现 LRU 缓存通常可以使用一些成熟的库,例如:
- Guava:Google 的 Guava 库中包含了一个强大的缓存实现,可以非常容易地实现基于 LRU 策略的缓存。
- Caffeine:一个高性能的缓存库,比 Guava 缓存更现代,也支持 LRU 缓存策略。
- Ehcache:一个广泛使用的开源 Java 分布式缓存框架,也支持 LRU 策略等。
这些工具和库提供了灵活而强大的缓存功能,可以轻松集成到 Java 后端项目中,帮助我们开发者实现高效的缓存策略。
解题思路(重点):
好了,通过以上的介绍,相信很多同学都对LRU有了一定的了解,那我们我们接下来就详细讲解下LRU缓存到底是如何实现的呢?
LRU(Least Recently Used)缓存算法是一种常用的替换策略,用于维护一个固定大小的缓存空间。其基本思路是:当缓存满时,最近最少使用的数据将被首先移除,以便为新的数据腾出空间。下面是实现 LRU 缓存算法的一般步骤和解题思路:
1. 数据结构选择
为了高效地实现 LRU 缓存,我们需要选用合适的数据结构。典型的实现是使用哈希表配合双向链表:
- 哈希表:保证了查找效率,能够在 O(1) 时间复杂度内查找节点是否存在。
- 双向链表:在链表头部添加最近访问的元素,在链表尾部移除最久未使用的元素,同时支持在 O(1) 时间内移除任何一个节点。
2. 初始化
初始化一个空的哈希表和一个空的双向链表。双向链表包含两个哨兵节点:头部节点和尾部节点,这两个节点分别代表链表的起始和终结,有助于简化边界条件的处理。
3. 访问元素(get操作)
当访问某个键值时:
- 如果键存在于哈希表中,说明缓存命中,需要将该节点移动到双向链表的头部,表示该节点为最近使用的节点。
- 如果键不存在,返回特定的值(如 -1),表示缓存未命中。
4. 添加/更新元素(put操作)
当需要添加或更新键值对时:
- 如果键已存在,更新其值,并将节点移动到双向链表的头部。
- 如果键不存在,首先在链表头部添加新节点,并在哈希表中注册该节点。
- 如果添加新节点后缓存容量超出限定大小,需要移除双向链表尾部的节点(最久未使用的数据),同时也需要在哈希表中删除相应的记录。
5. 维护双向链表
- 添加到头部:节点总是在双向链表的头部添加,因为头部反映了最近的访问。
- 从链表中删除节点:当节点被访问后,该节点从当前位置删除,并重新添加到链表头部。如果需要为新节点腾出空间,也是从链表尾部移除节点。
6. 尾部节点移除
当缓存达到其容量限制时,需要从双向链表的尾部移除最不常用的节点,并同时从哈希表中删除对应的键值对。
图解分析:
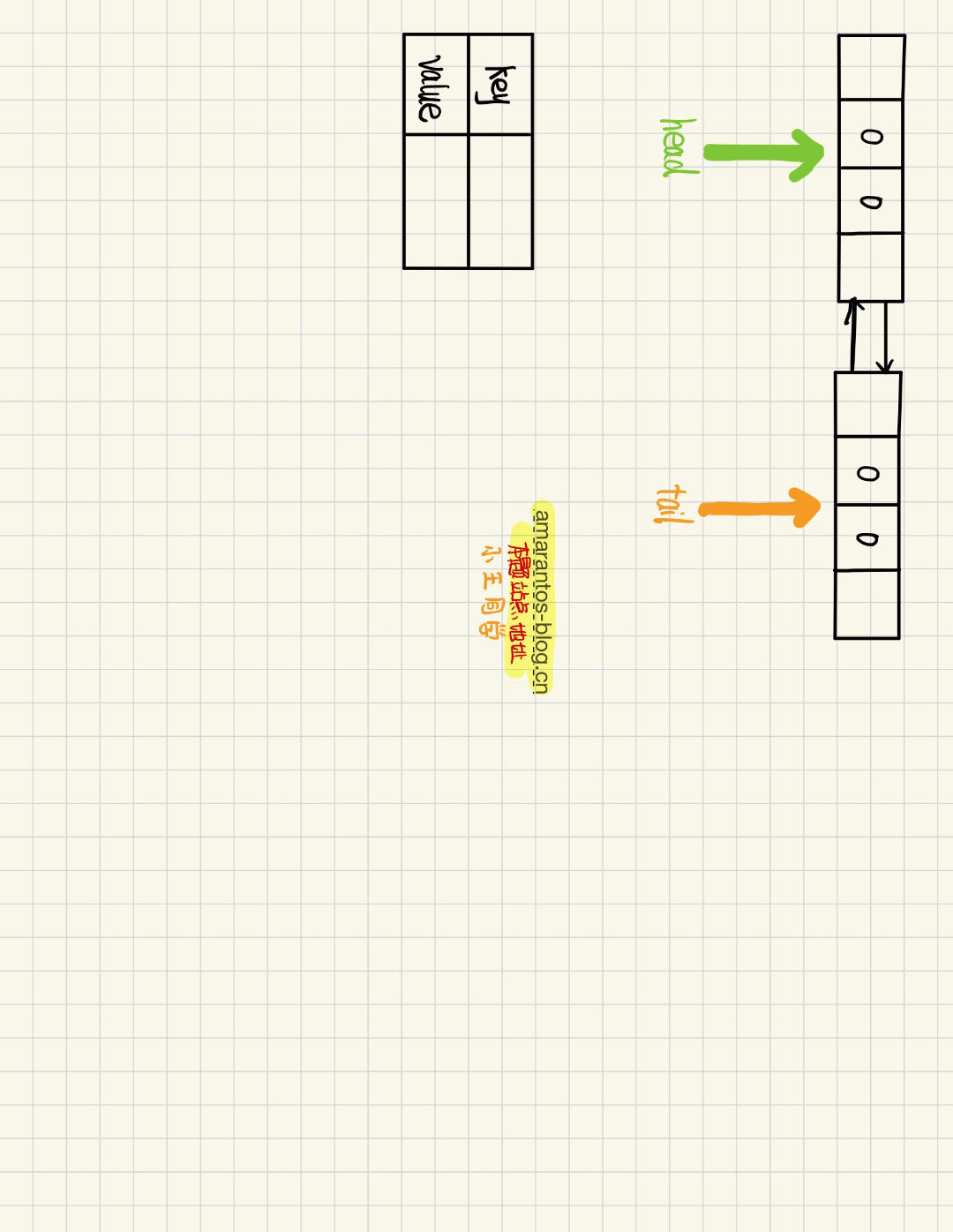
首先我们准备好头结点和尾节点
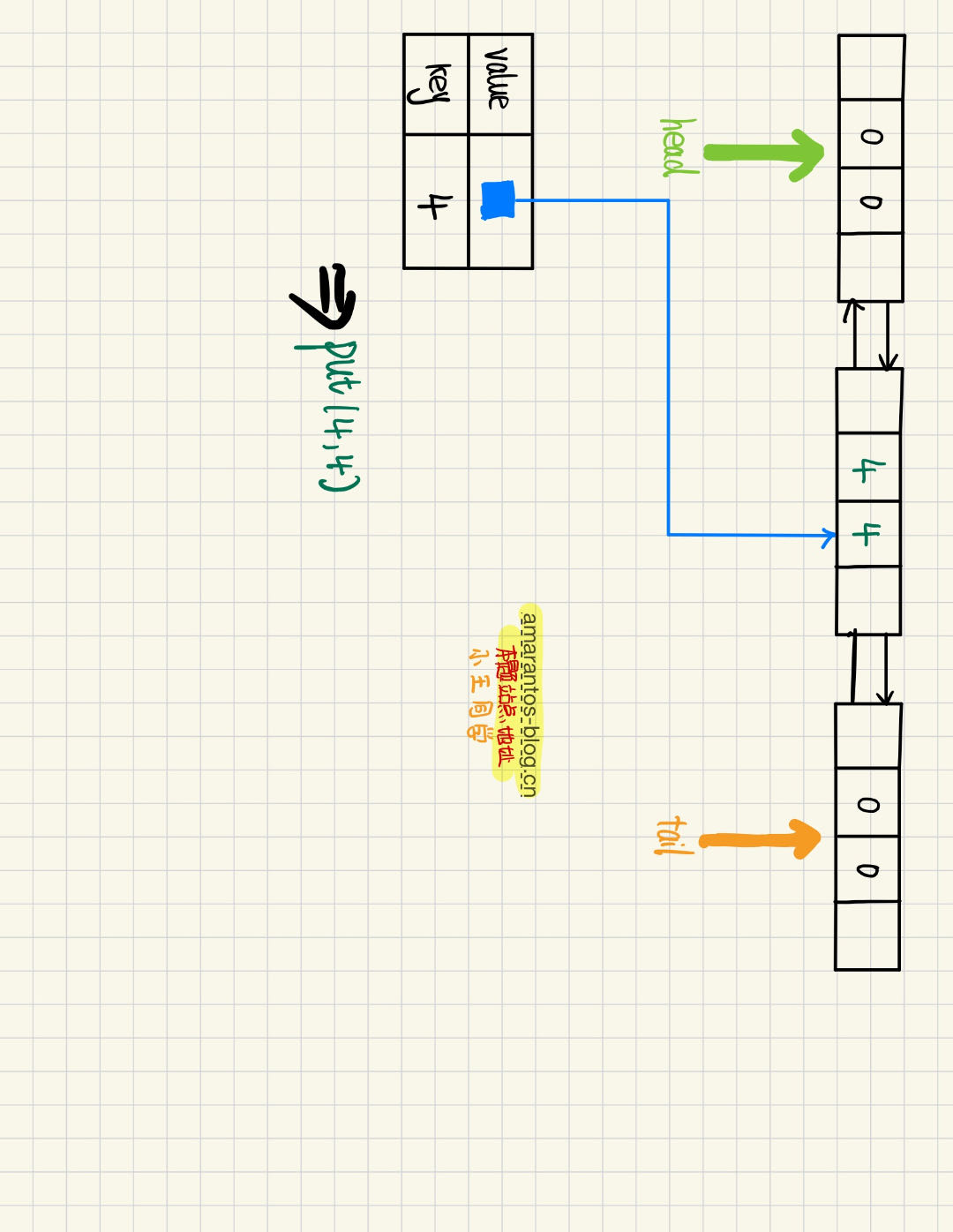
此时插入一个Node,key为4,val为4
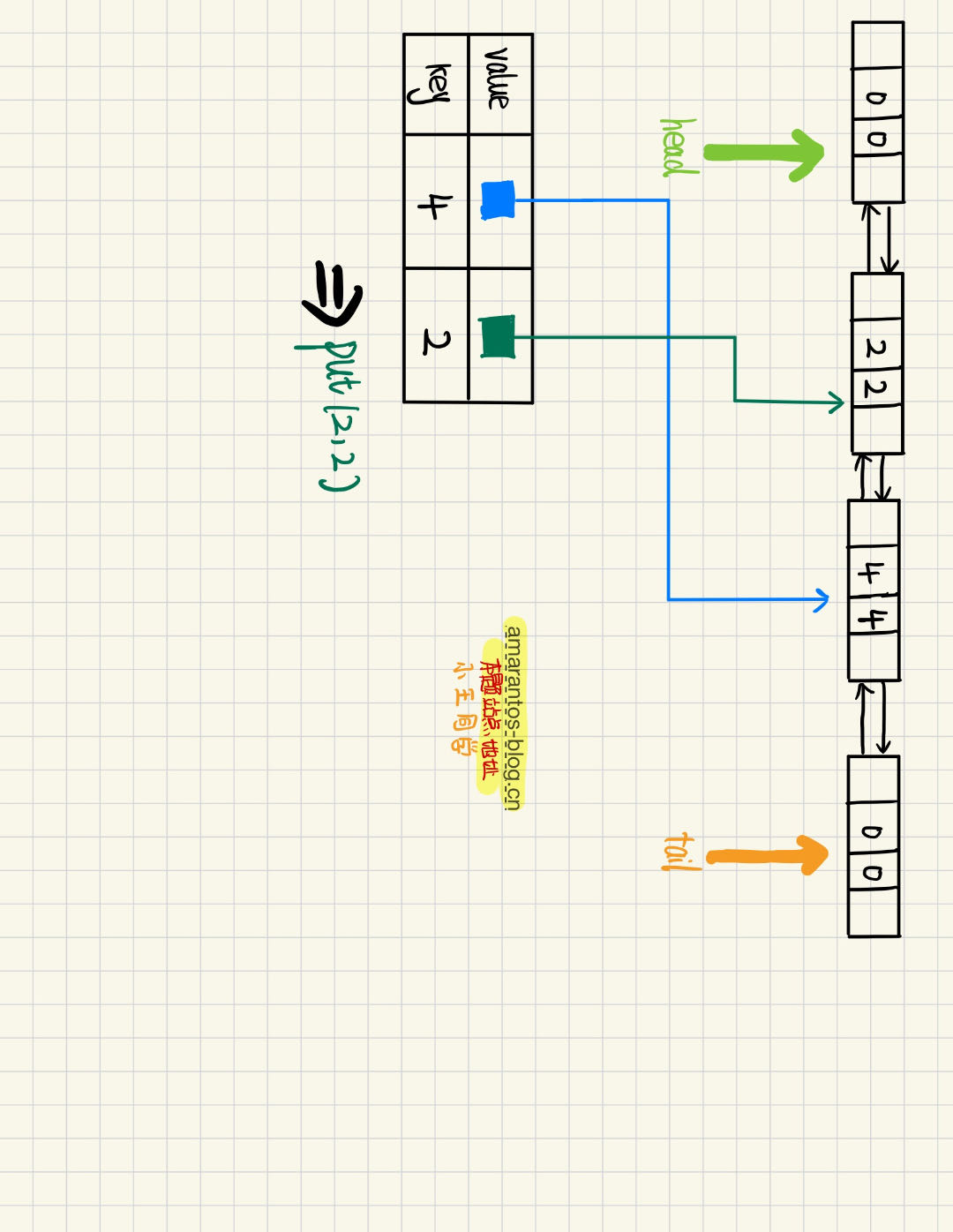
此时再插入一个Node,key为2,val为2
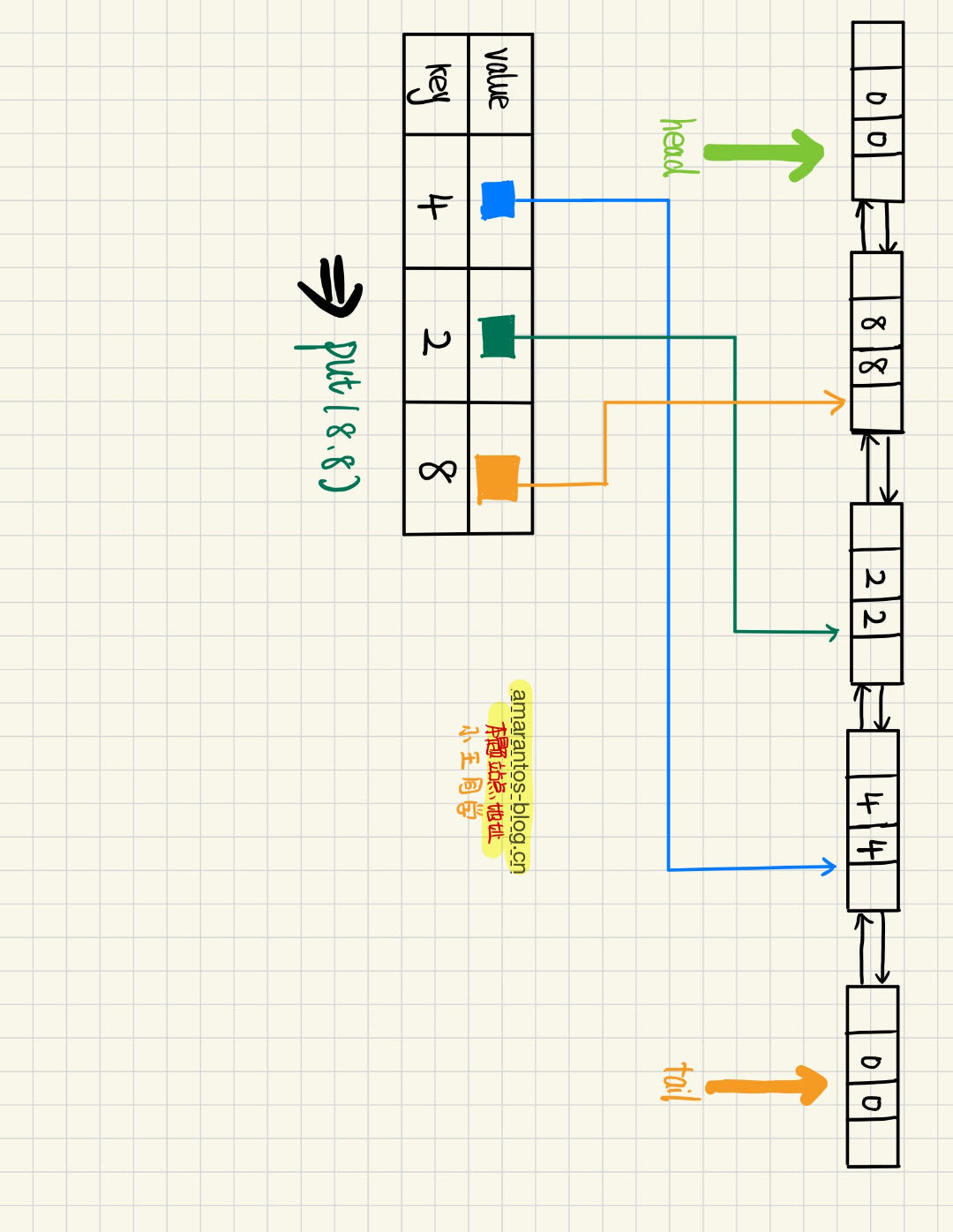
此时再插入一个Node,key为8,val为8
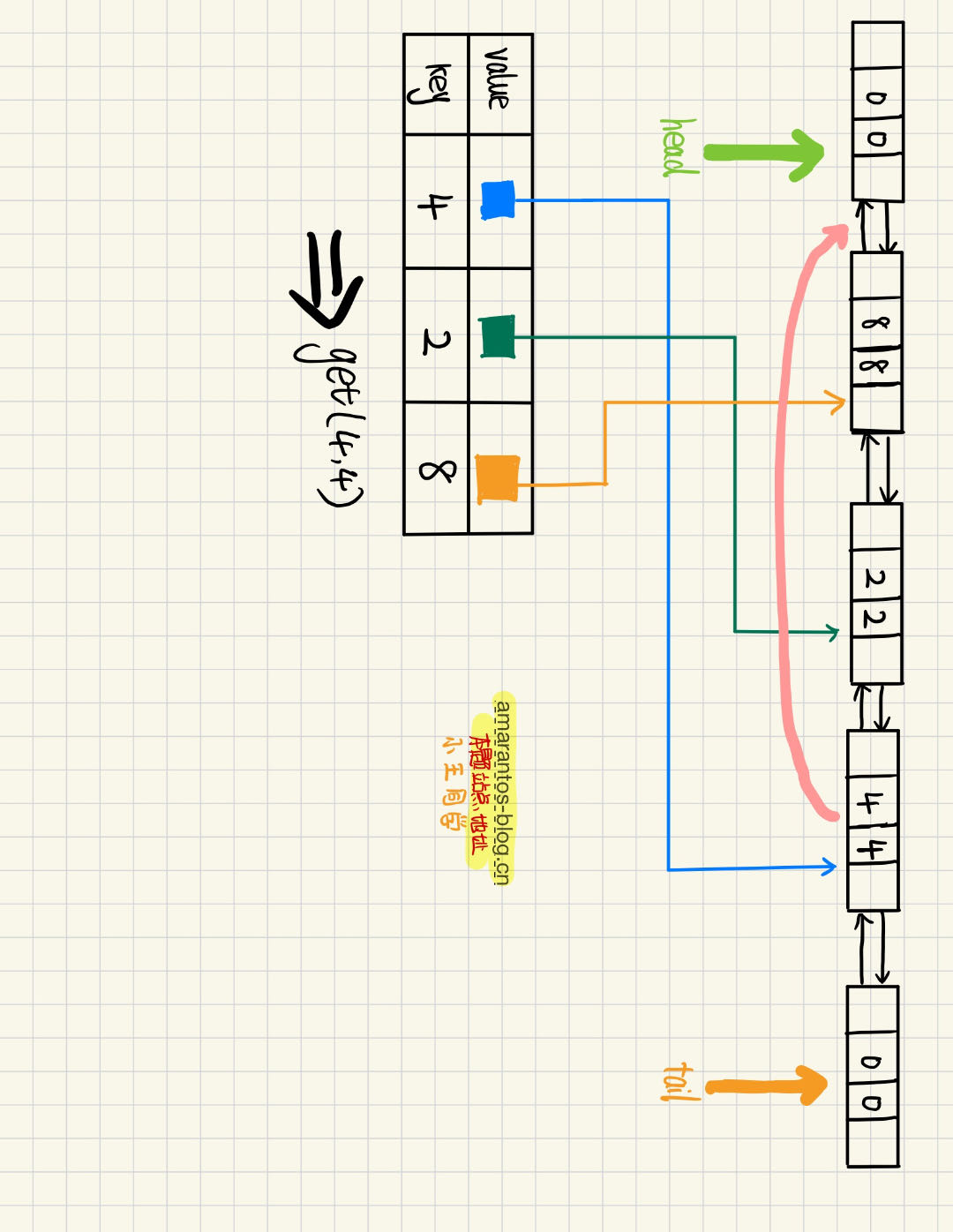
此时我们获取(4,4)这个节点,获取完我们需要将它放到头部
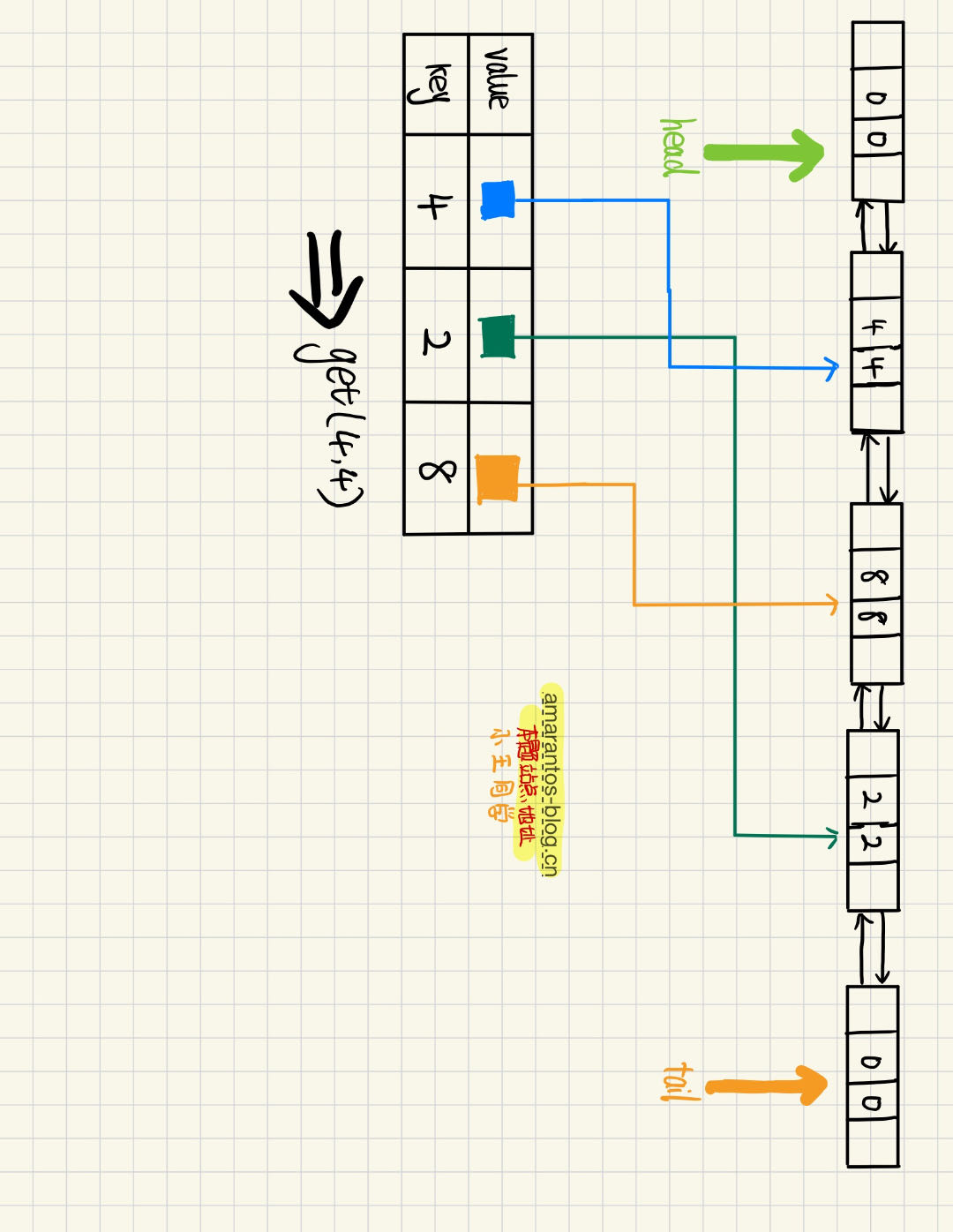
剩下我们可以再插入一个节点,然后设置capacity为3,这时候我们需要先将尾部的2,2删除,然后再插入到头部新节点
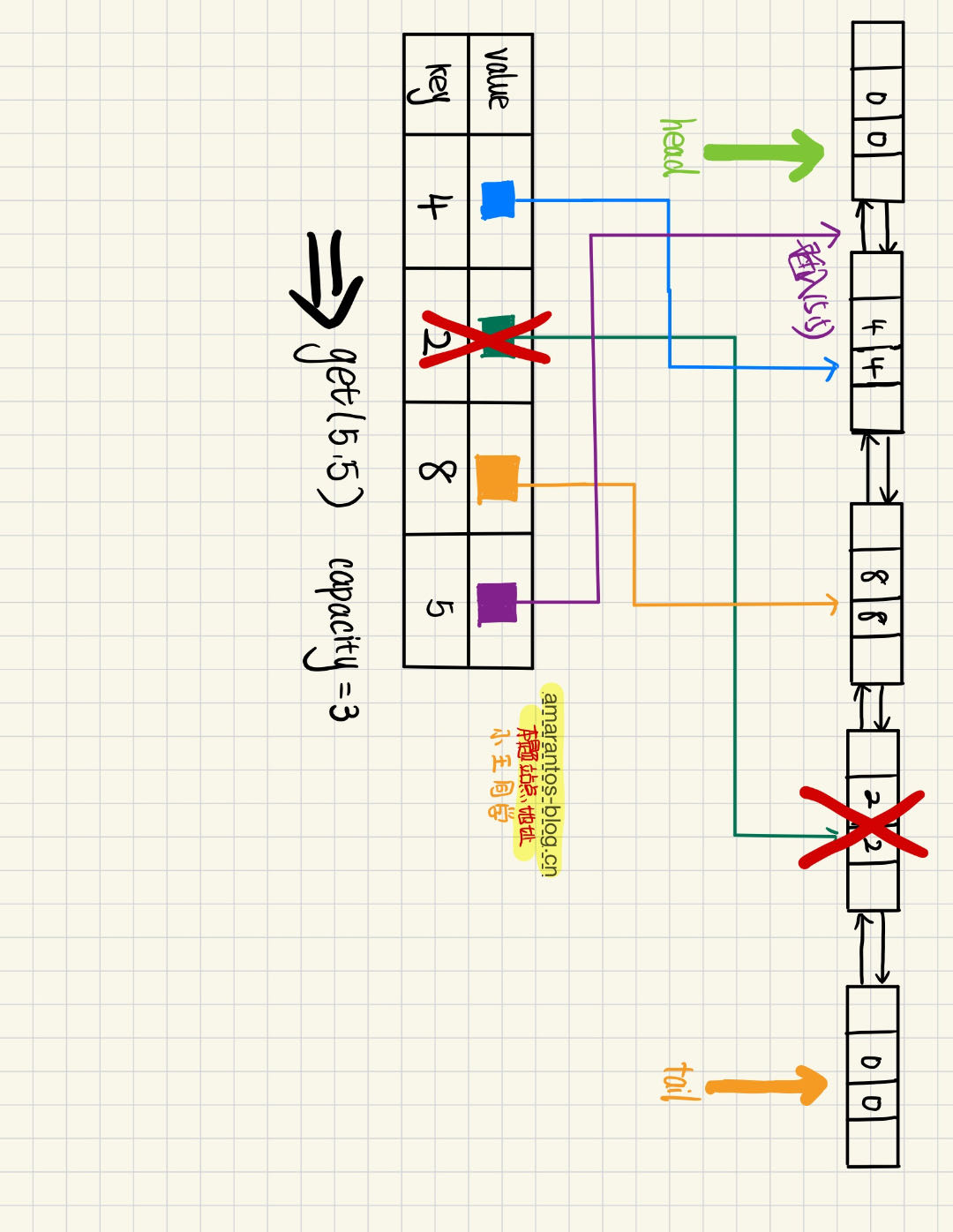
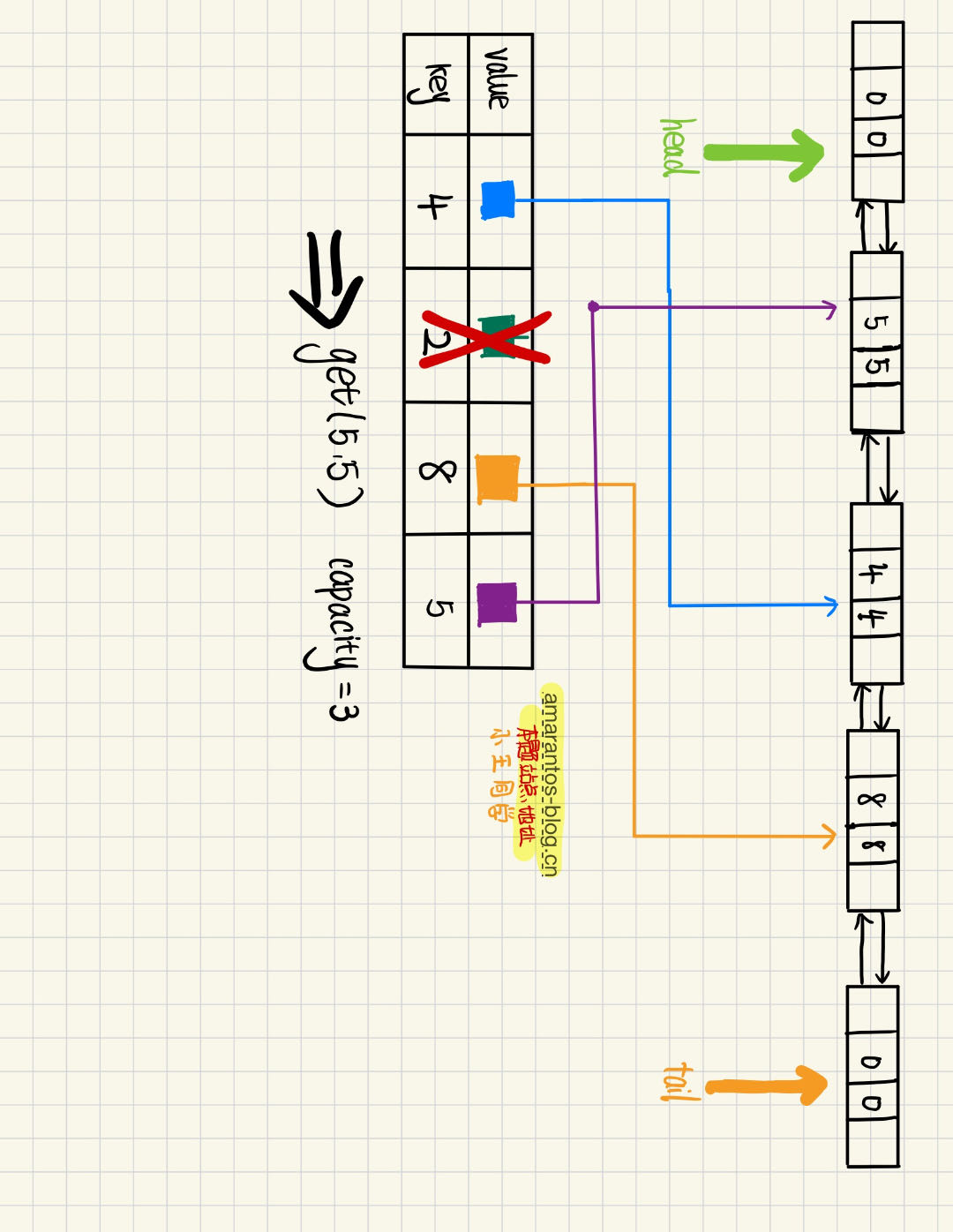
这里我们先删除key为2的节点,然后才插入key为5的节点。
下面我们一起来看代码实现:
class LRUCache {
// 缓存容量
int capacity;
// 尾部节点
ListNode tail;
// 头部节点
ListNode head;
// 键值对存储映射
HashMap<Integer, ListNode> hashMap = new HashMap();
public LRUCache(int capacity) {
this.capacity = capacity;
this.head = new ListNode(-1, -1);
this.tail = new ListNode(-1, -1);
head.next = tail;
tail.pre = head;
}
public int get(int key) {
// 检查键是否存在
if (!hashMap.containsKey(key)) {
return -1;
}
// 从哈希表中获取节点
ListNode currNode = hashMap.get(key);
// 移动到头部,表示最近使用
remove(currNode);
addHeadNode(currNode);
return currNode.val;
}
public void put(int key, int value) {
// 如果键已存在,更新其值并移至头部
if (hashMap.containsKey(key)) {
ListNode currNode = hashMap.get(key);
currNode.val = value;
remove(currNode);
addHeadNode(currNode);
} else {
// 创建新节点,加入头部
ListNode newNode = new ListNode(key, value);
hashMap.put(key, newNode);
addHeadNode(newNode);
// 如果超出容量,移除尾部最久未使用的节点
if (hashMap.size() > capacity) {
ListNode tail = removeTail();
hashMap.remove(tail.key);
}
}
}
// 将节点添加到头部
public void addHeadNode(ListNode node) {
node.pre = head;
node.next = head.next;
head.next.pre = node;
head.next = node;
}
// 从链表中删除节点
public void remove(ListNode node) {
node.next.pre = node.pre;
node.pre.next = node.next;
}
// 移除尾部节点
ListNode removeTail() {
ListNode currNode = tail.pre;
remove(currNode);
return currNode;
}
static class ListNode {
int key;
int val;
ListNode pre;
ListNode next;
// 构造函数初始化节点
public ListNode(int key, int val) {
this.key = key;
this.val = val;
this.pre = null;
this.next = null;
}
}
}
注释已经写得很详细了,我在这里就不做过多的解释,整理不易,喜欢我的可以点个赞或收藏,谢谢大家!


评论区