



Leetcode 无重复字符的最长子串
解题思路:
这道题目我们可以使用滑动窗口的思路。
滑动窗口是一种管理两个指针(通常是窗口的起始和终止位置)的技术,通过这两个指针可以表示字符串中的一个区间。当这个区间内的元素满足题目要求时,我们尝试扩大窗口的大小(即移动结束指针);当不满足要求时,我们需要通过移动开始指针来缩小窗口,直到再次满足条件。
无重复字符的最长子串
关键词:无重复,最长
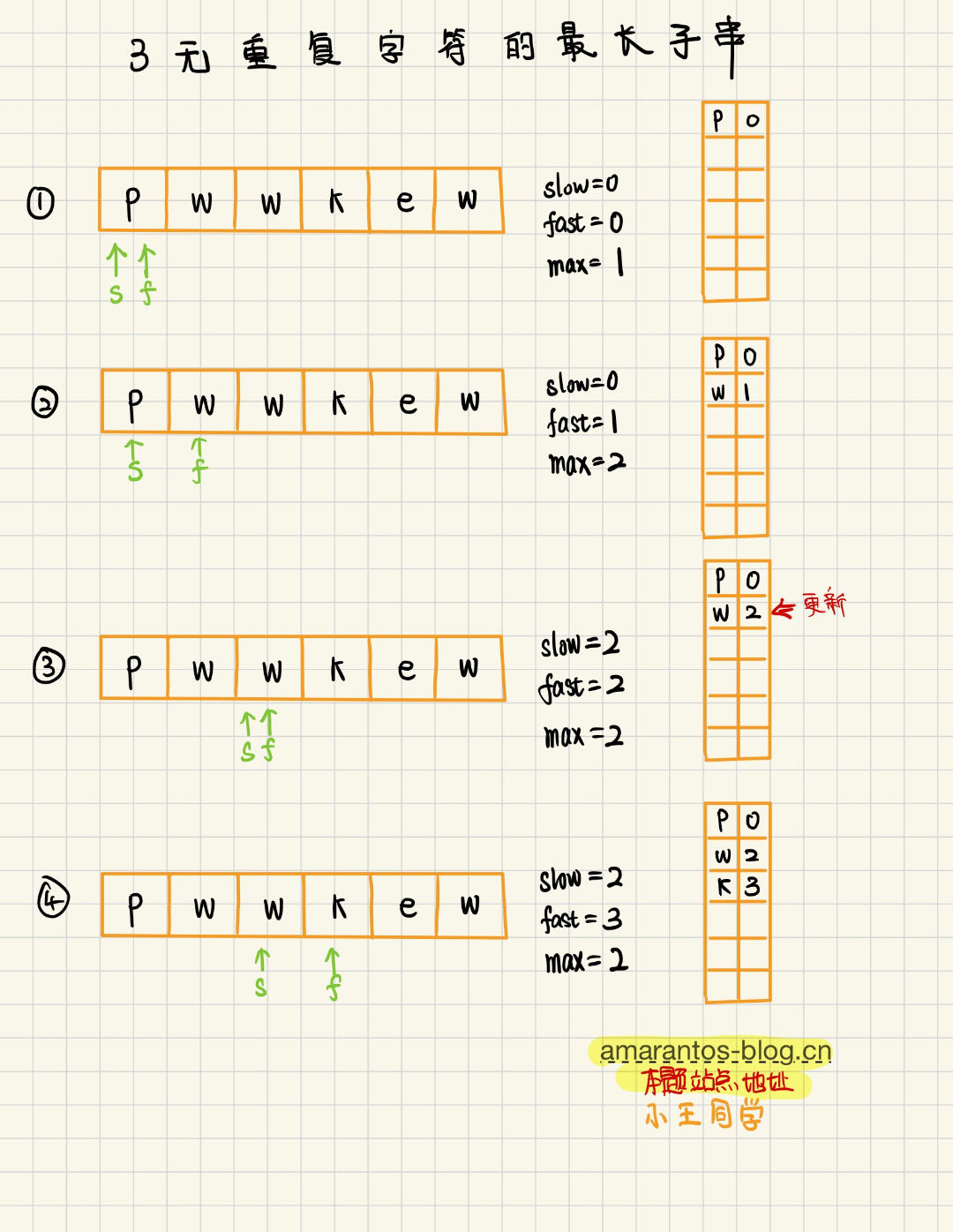
我们肯定要记录哪个字符是重复的吧,这个我们可以使用HashMap来进行存储对应的字符,key为字符,value为字符对应的下标。然后呢,我们准备两个指针来控制滑动窗口的大小,这两个指针为fast和slow,初始化的话我们都从0开始,最后我们题目需要返回一个结果值,这个结果值就是无重复字符的最长子串的大小,我们定义为max。
首先,我们循环遍历这个字符串,这里我们可以先把字符串转换成数组,方便我们后续对字符串的读取,接着判断hashmap里面是否存在当前的字符,如果存在的话,说明遇到重复的字符了,那么我们该如何处理窗口大小呢?
我们思考一下,是不是应该将slow的指针进行变化了。因为我们每次循环遍历这个字符串的时候fast已经在增加了,我们只需要考虑slow的指针变化,这时候我们需要将slow使之指向重复字符上一次出现位置的下一个位置,注意这句话的理解, 我们将slow指向重复字符的上一次出现的位置的下一个位置。这一步操作的目的是为了确保从 slow 到 fast(包括 fast 指向的位置)的窗口中不存在重复的字符。
当 fast 指针在字符串中前进并发现一个重复字符时,这意味着当前考虑的窗口(从 slow 到 fast)已经包含了一个与 fast 指向相同的字符。为了维护窗口内的字符唯一性,我们需要排除旧的重复字符及其之前的所有字符。通过将 slow 指针移动到重复字符之前的位置的下一个位置,我们可以保证新的窗口不包含重复字符。
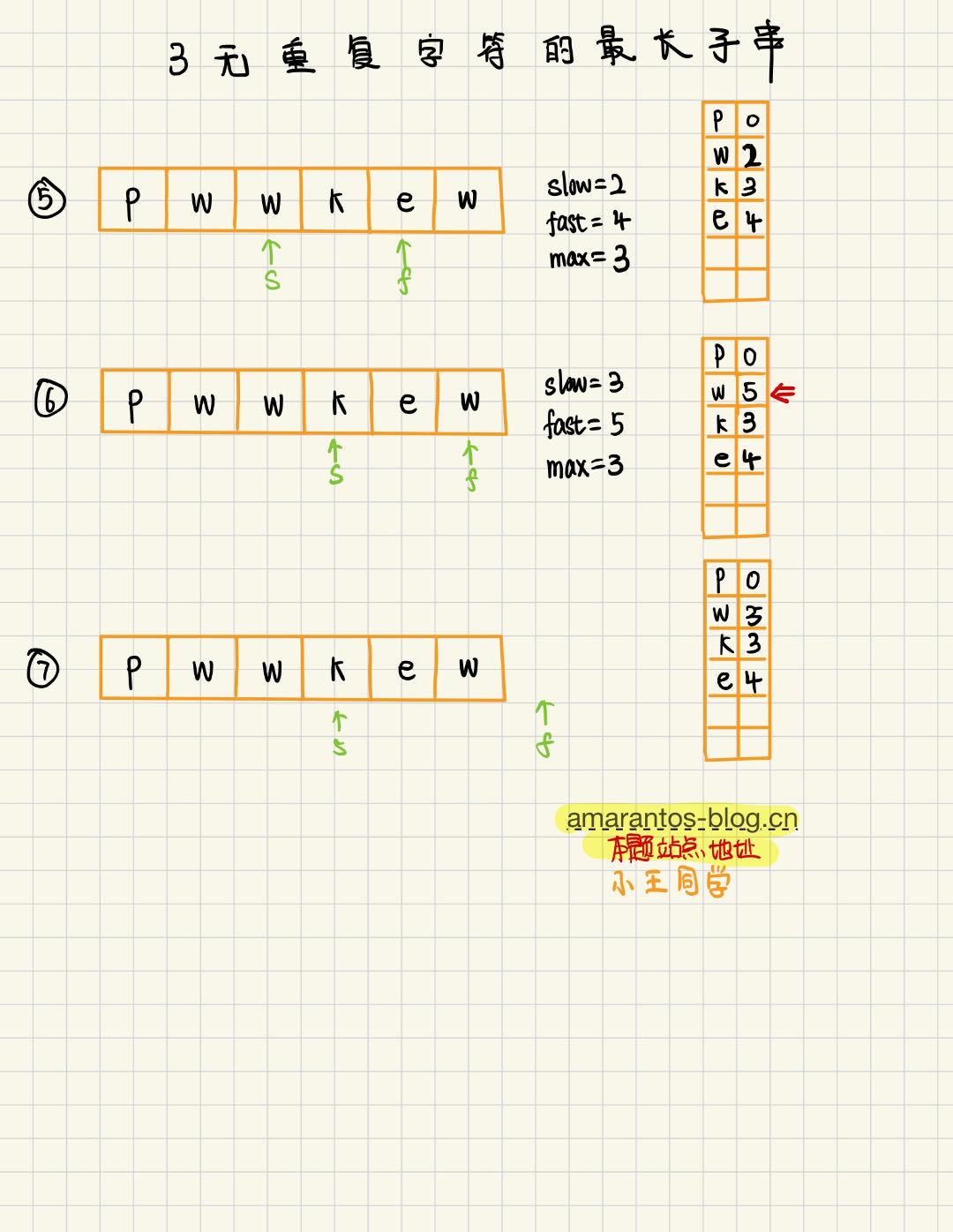
比如下面这张图,当f走到第二个w的时候,s需要走到w上一次出现的位置的下一个位置,那么就是w的第二次出现的位置,再例如,当f走到第三个w的位置时候,s需要指向w上一次出现的位置(即第二次出现w的位置)的下一个位置,即k的位置。这一点是最重要的,如果理解了这个slow的更新逻辑,那么下面就好说了
我们不管更新完slow还是没更新slow,我们都需要将当前遍历的fast装入到hashmap里面,并且紧接着更新我们的结果值max,max的每次计算都是取的max和fast-slow+1这两个值的最大值,fast-slow+1 也就是我们计算的不重复的字符的长度。
最后返回max的值即可。
具体的流程可以看下面手写的步骤图。
代码实现:
class Solution {
public int lengthOfLongestSubstring(String s) {
// 如果输入的字符串为空或长度为0,直接返回0
if(s == null || s.length() == 0){
return 0;
}
// 将字符串转换成字符数组
char[] ch = s.toCharArray();
// 快指针
int fast = 0;
// 慢指针
int slow = 0;
// 用于记录最大无重复字符的子字符串长度
int max = 0;
// 哈希表用于存储字符和其最新的索引位置
HashMap<Character, Integer> hashmap = new HashMap();
// 遍历字符数组
for(; fast < ch.length; fast++){
// 如果字符已存在于哈希表中,说明出现了重复字符
if(hashmap.containsKey(ch[fast])){
// 更新慢指针的位置到重复字符的下一个位置,但不回退
slow = Math.max(slow, hashmap.get(s.charAt(fast)) + 1);
}
// 更新哈希表中的字符位置
hashmap.put(ch[fast], fast);
// 计算当前无重复字符的子字符串长度并更新最大长度
max = Math.max(max, fast - slow + 1);
}
// 返回最大长度
return max;
}
}
复杂度分析
- 时间复杂度:O(N),其中 N 是字符串的长度。每个字符只被处理一次。
- 空间复杂度:O(min(M, N)),其中 M 是字符集的大小(如 ASCII 字符集是 128)。这是因为哈希表最多存储这么多键值对。


评论区