



Leetcode 459.重复的子字符串(画图分析)
LeetCode 459. Repeated Substring Pattern
给定一个非空的字符串,判断它是否可以由它的一个子串重复多次构成。给定的字符串只含有小写英文字母,并且长度不超过10000。
示例 1:
- 输入: "abab"
- 输出: True
- 解释: 可由子字符串 "ab" 重复两次构成。
示例 2:
- 输入: "aba"
- 输出: False
示例 3:
- 输入: "abcabcabcabc"
- 输出: True
- 解释: 可由子字符串 "abc" 重复四次构成。 (或者子字符串 "abcabc" 重复两次构成。)
解题思路:
如果一个字符串 s可以由它的子串 s1 多次重复构成,那么:
- s 的长度肯定是 s1 的长度的倍数
- s1 肯定 是 s 的前缀
- 对于任意的 s[i] = s[i - s1.length]
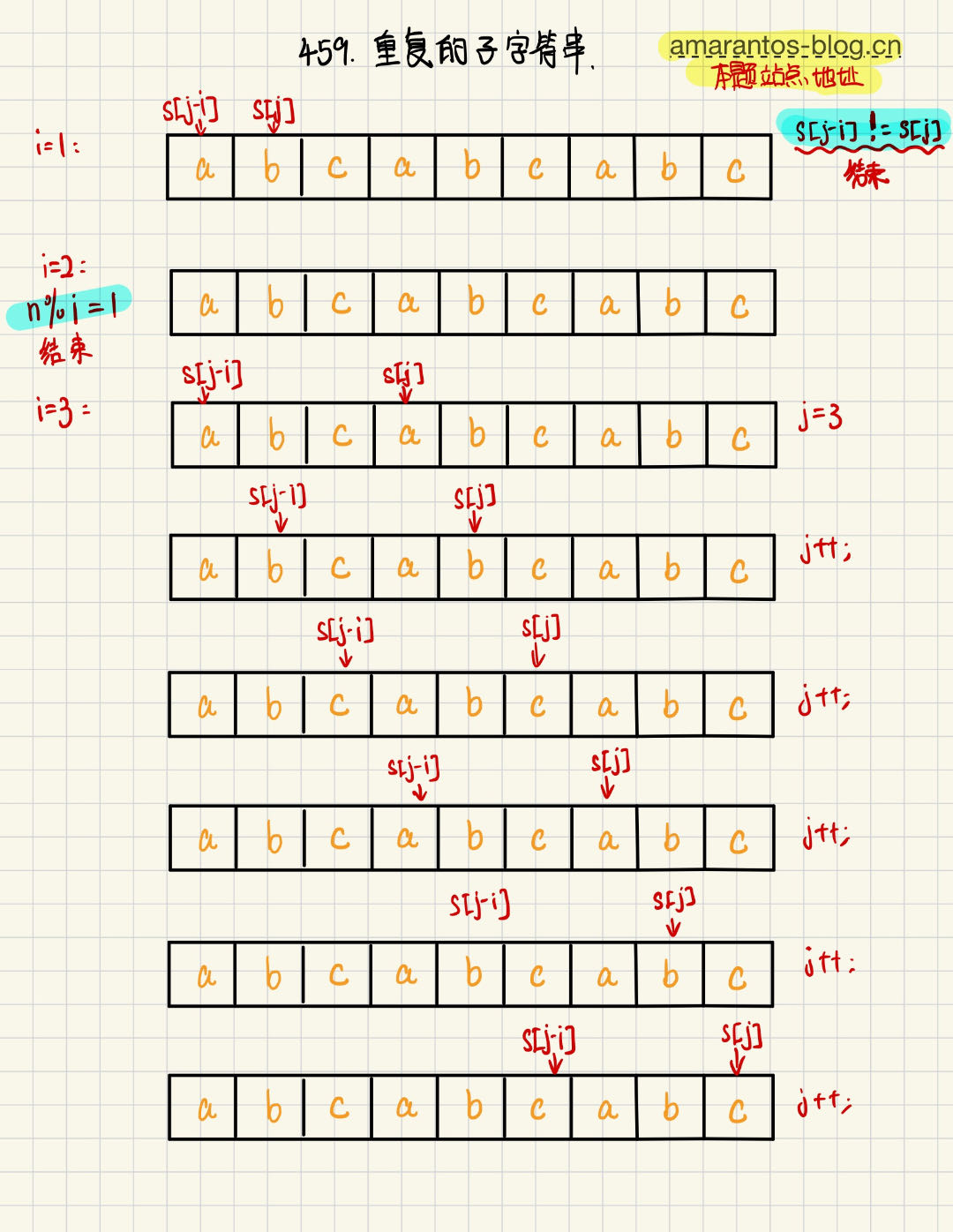
其实就是 我们假设 字符串 s 是由 i 个元素重复构建的,知道子字符串的长度 i 就好办了,这个 i 就是我们去依次判断这个重复的子字符串的长度,这一点理解很重要,接着我们再次遍历整个字符串,依次去比较s[j] 和 s[j-i](j 是用来从位置 i 开始遍历字符串的索引 ),也就是子字符串s1依次和字符串s比较,一旦发现有不一样的元素,那么我们假设的由i个元素重复构建的结论就否定掉了,重新让i++进入下一次循环,再次假设子字符串的长度进行判断。
代码实现:
java
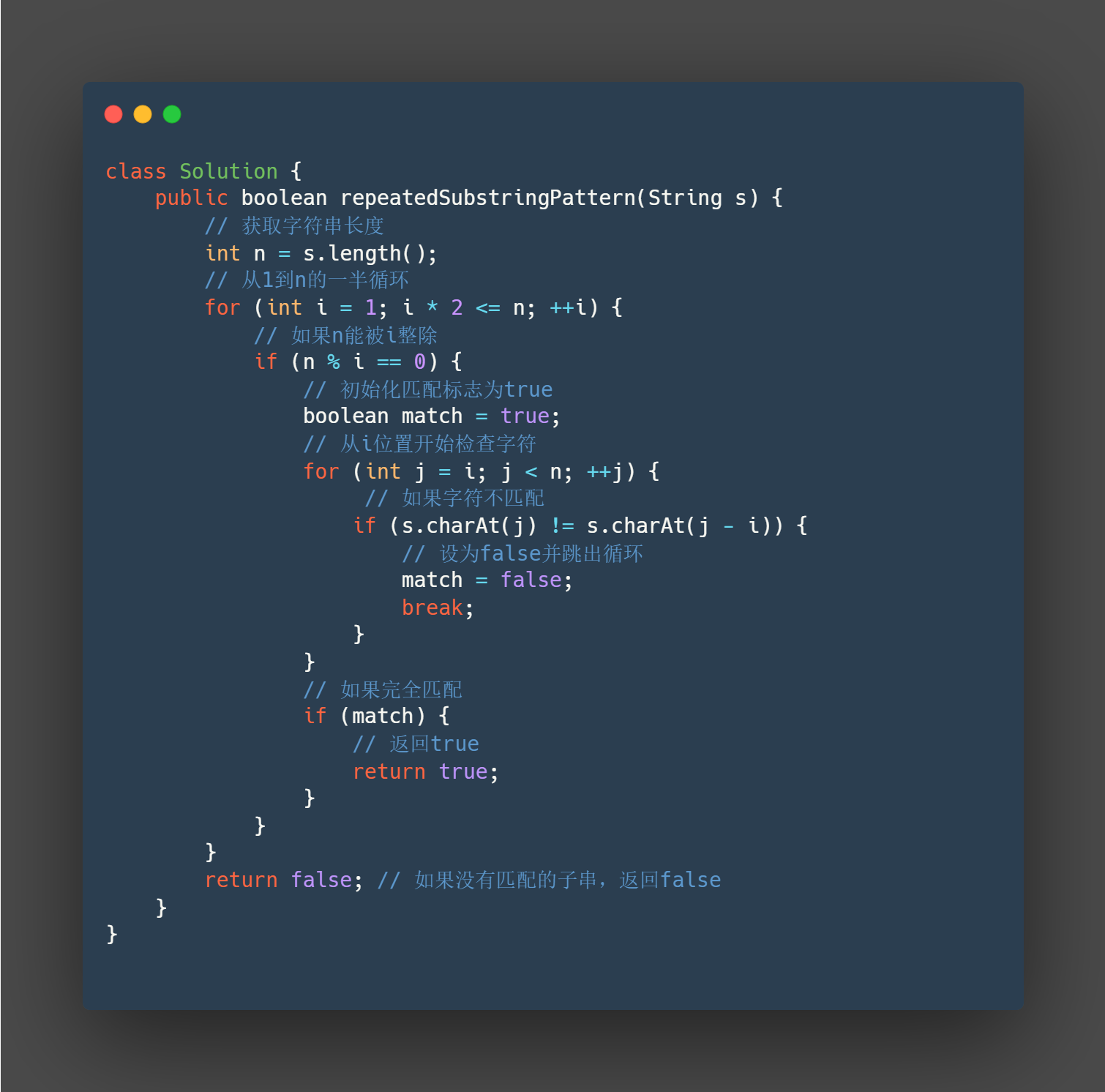
class Solution {
public boolean repeatedSubstringPattern(String s) {
// 获取字符串长度
int n = s.length();
// 从1到n的一半循环
for (int i = 1; i * 2 <= n; ++i) {
// 如果n能被i整除
if (n % i == 0) {
// 初始化匹配标志为true
boolean match = true;
// 从i位置开始检查字符
for (int j = i; j < n; ++j) {
// 如果字符不匹配
if (s.charAt(j) != s.charAt(j - i)) {
// 设为false并跳出循环
match = false;
break;
}
}
// 如果完全匹配
if (match) {
// 返回true
return true;
}
}
}
return false; // 如果没有匹配的子串,返回false
}
}
举例说明:
当给定字符串 s 为 "abcabcabc" 时,我们可以通过一个示例来说明循环条件 i * 2 <= n 的作用。
首先,计算字符串 s 的长度为 n = 9。
然后,我们开始循环,从 i = 1 开始递增。对于每个 i,我们检查是否存在一个长度为 i 的子串,能够将整个字符串 s 分割成等长的部分。
-
当
i = 1时:- 子串长度为 1,即每个字符本身。
- 由于
n % i = 0,子串长度能够整除字符串长度,因此满足条件。 - 开始内层循环,从
j = i = 1开始,检查是否有连续的字符与前面的字符相等。 - 检查第二个字符是否与第一个字符相等:
s[1] = 'b',s[1 - 1] = s[0] = 'a',不相等,子串不匹配。 - 结束内层循环,没有找到满足条件的子串。
-
当
i = 2时:- 子串长度为 2。
- 由于
n % i = 1,子串长度不能整除字符串长度,不满足条件。 - 跳过这个子串长度,继续下一个循环。
-
当
i = 3时:- 子串长度为 3。
- 由于
n % i = 0,子串长度能够整除字符串长度,满足条件。 - 开始内层循环,从
j = i = 3开始,检查是否有连续的字符与前面的字符相等。 - 检查第四个字符是否与第一个字符相等:
s[3] = 'a',s[3 - 3] = s[0] = 'a',相等。 - 检查第五个字符是否与第二个字符相等:
s[4] = 'b',s[4 - 3] = s[1] = 'b',相等。 - 检查第六个字符是否与第三个字符相等:
s[5] = 'c',s[5 - 3] = s[2] = 'c',相等。 - 继续循环,直到检查完整个字符串,发现所有字符都与第一个子串相等,满足条件。
- 返回
true,表示存在重复子串。
为什么i从1开始?
在这个算法中,i 从 1 开始是因为我们要考虑最小长度的子串。我们需要检查是否存在一个长度为 1 的子串,能够将整个字符串 s 分割成等长的部分。
如果 i 从 0 开始,那么在 n % i 的计算中会出现除以 0 的情况,而这是不允许的。所以从1开始很合理~
为什么 i 要乘以2呢?
循环条件 i * 2 <= n 的目的是为了避免重复检查过长的子串长度。因为重复子串的长度最长不会超过原始字符串的一半,所以我们只需要检查长度不超过 n/2 的子串是否能够构成重复。通过该条件,我们可以减少循环的次数,提高代码的效率。
python3
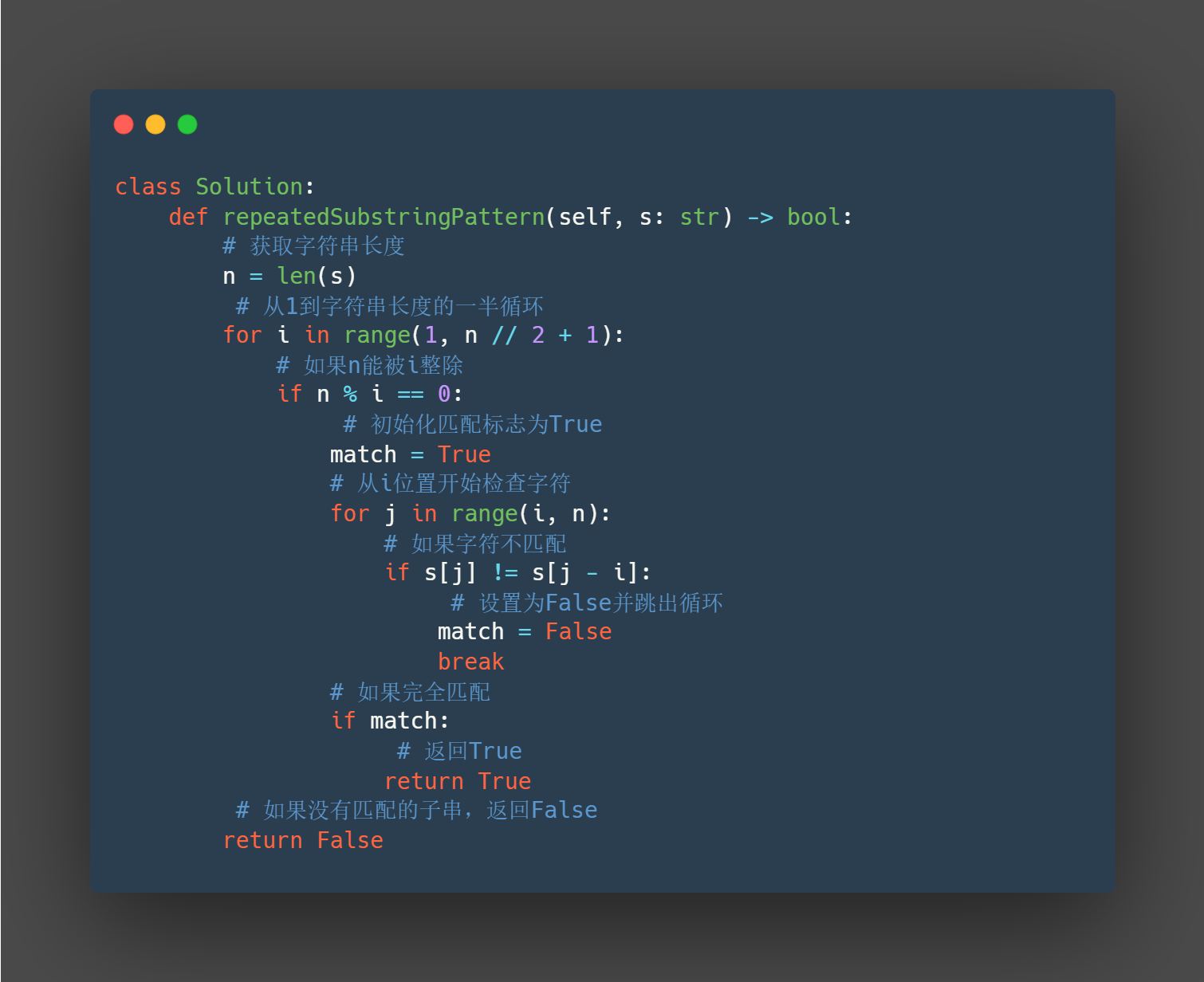
class Solution:
def repeatedSubstringPattern(self, s: str) -> bool:
# 获取字符串长度
n = len(s)
# 从1到字符串长度的一半循环
for i in range(1, n // 2 + 1):
# 如果n能被i整除
if n % i == 0:
# 初始化匹配标志为True
match = True
# 从i位置开始检查字符
for j in range(i, n):
# 如果字符不匹配
if s[j] != s[j - i]:
# 设置为False并跳出循环
match = False
break
# 如果完全匹配
if match:
# 返回True
return True
# 如果没有匹配的子串,返回False
return False
c++
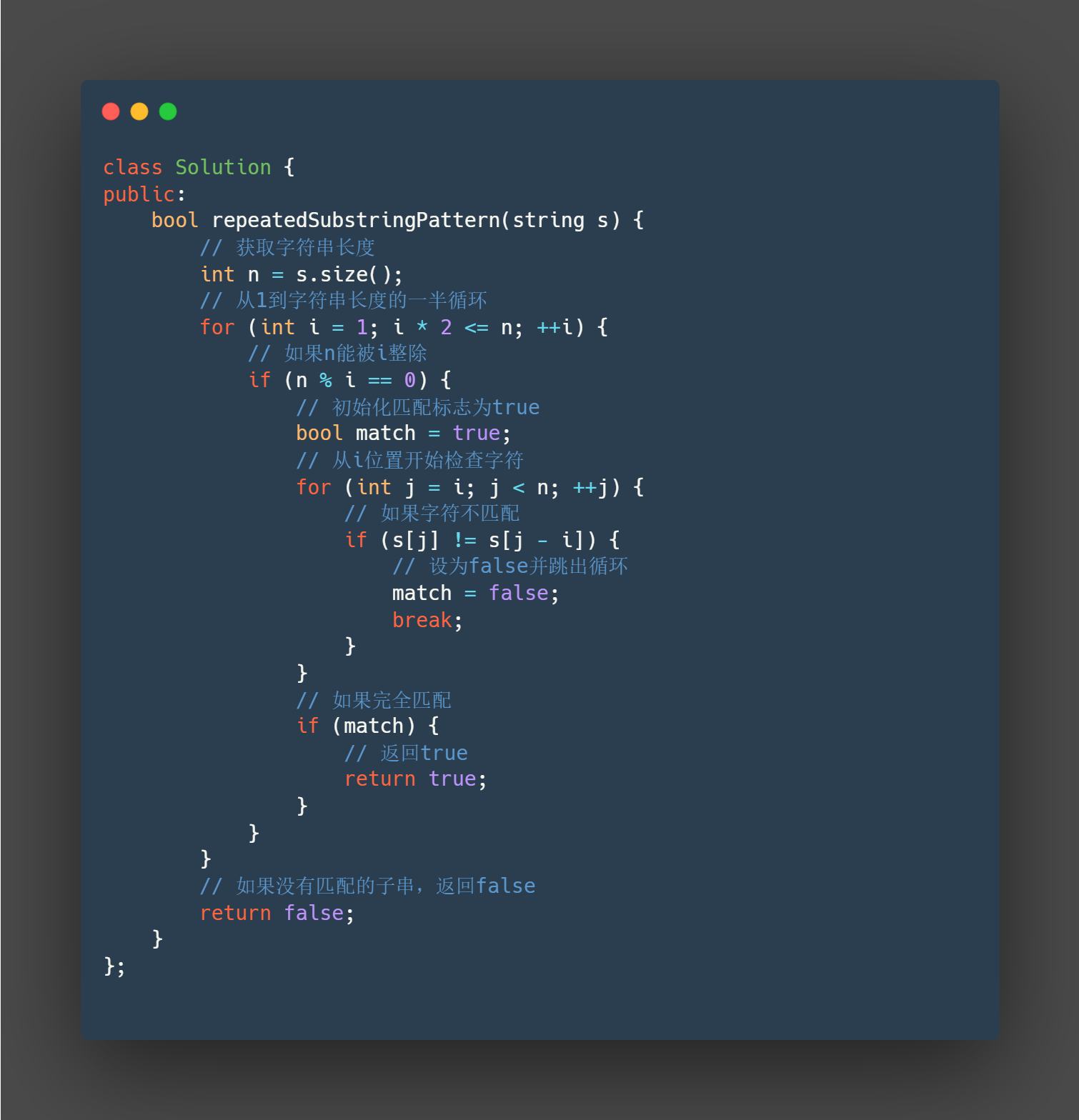
class Solution {
public:
bool repeatedSubstringPattern(string s) {
// 获取字符串长度
int n = s.size();
// 从1到字符串长度的一半循环
for (int i = 1; i * 2 <= n; ++i) {
// 如果n能被i整除
if (n % i == 0) {
// 初始化匹配标志为true
bool match = true;
// 从i位置开始检查字符
for (int j = i; j < n; ++j) {
// 如果字符不匹配
if (s[j] != s[j - i]) {
// 设为false并跳出循环
match = false;
break;
}
}
// 如果完全匹配
if (match) {
// 返回true
return true;
}
}
}
// 如果没有匹配的子串,返回false
return false;
}
};


评论区