



Leetcode 28.找出字符串中第一个匹配项的下标(画图分析)
实现 strStr() 函数。
给定一个 haystack 字符串和一个 needle 字符串,在 haystack 字符串中找出 needle 字符串出现的第一个位置 (从0开始)。如果不存在,则返回 -1。
示例 1: 输入: haystack = "hello", needle = "ll" 输出: 2
示例 2: 输入: haystack = "aaaaa", needle = "bba" 输出: -1
说明: 当 needle 是空字符串时,我们应当返回什么值呢?这是一个在面试中很好的问题。 对于本题而言,当 needle 是空字符串时我们应当返回 0 。这与C语言的 strstr() 以及 Java的 indexOf() 定义相符。
解题思路:
双指针法:
- 首先准备两个指针
i和j,分别指向haystack和needle的起始位置,即初始值为0。 - 进入循环,循环条件是
i小于haystack的长度且j小于needle的长度。这是为了确保两个指针都在有效范围内。 - 在循环中,首先比较
haystack.charAt(i)和needle.charAt(j),即当前位置的字符是否匹配。- 如果匹配,说明找到了一个相同的字符,将两个指针都向后移动一位,即
i++和j++。 - 如果不匹配,说明当前字符不匹配,需要重新开始匹配。将
i回退到上一次匹配开始的位置之后一位(即i - j + 1),并将j重置为0,重新开始匹配下一个字符。
- 如果匹配,说明找到了一个相同的字符,将两个指针都向后移动一位,即
- 循环结束后,检查
j是否等于needle的长度。如果等于,说明已经完全匹配了needle,返回匹配开始的位置i - j;否则,未找到完全匹配的子串,返回-1表示未找到。
下面是画图分析:

代码实现:
java
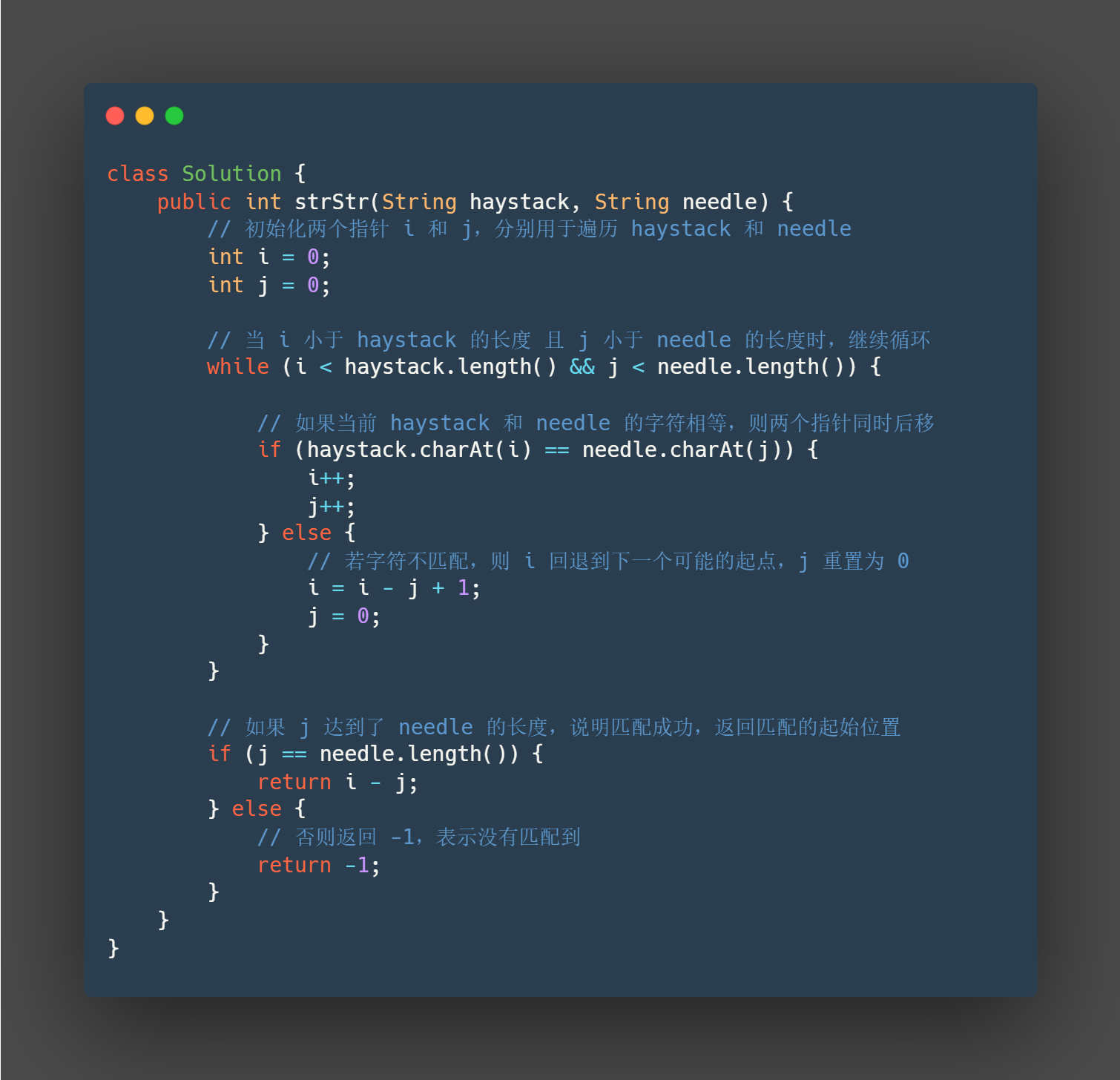
class Solution {
public int strStr(String haystack, String needle) {
// 初始化两个指针 i 和 j,分别用于遍历 haystack 和 needle
int i = 0;
int j = 0;
// 当 i 小于 haystack 的长度 且 j 小于 needle 的长度时,继续循环
while (i < haystack.length() && j < needle.length()) {
// 如果当前 haystack 和 needle 的字符相等,则两个指针同时后移
if (haystack.charAt(i) == needle.charAt(j)) {
i++;
j++;
} else {
// 若字符不匹配,则 i 回退到下一个可能的起点,j 重置为 0
i = i - j + 1;
j = 0;
}
}
// 如果 j 达到了 needle 的长度,说明匹配成功,返回匹配的起始位置
if (j == needle.length()) {
return i - j;
} else {
// 否则返回 -1,表示没有匹配到
return -1;
}
}
}
python3
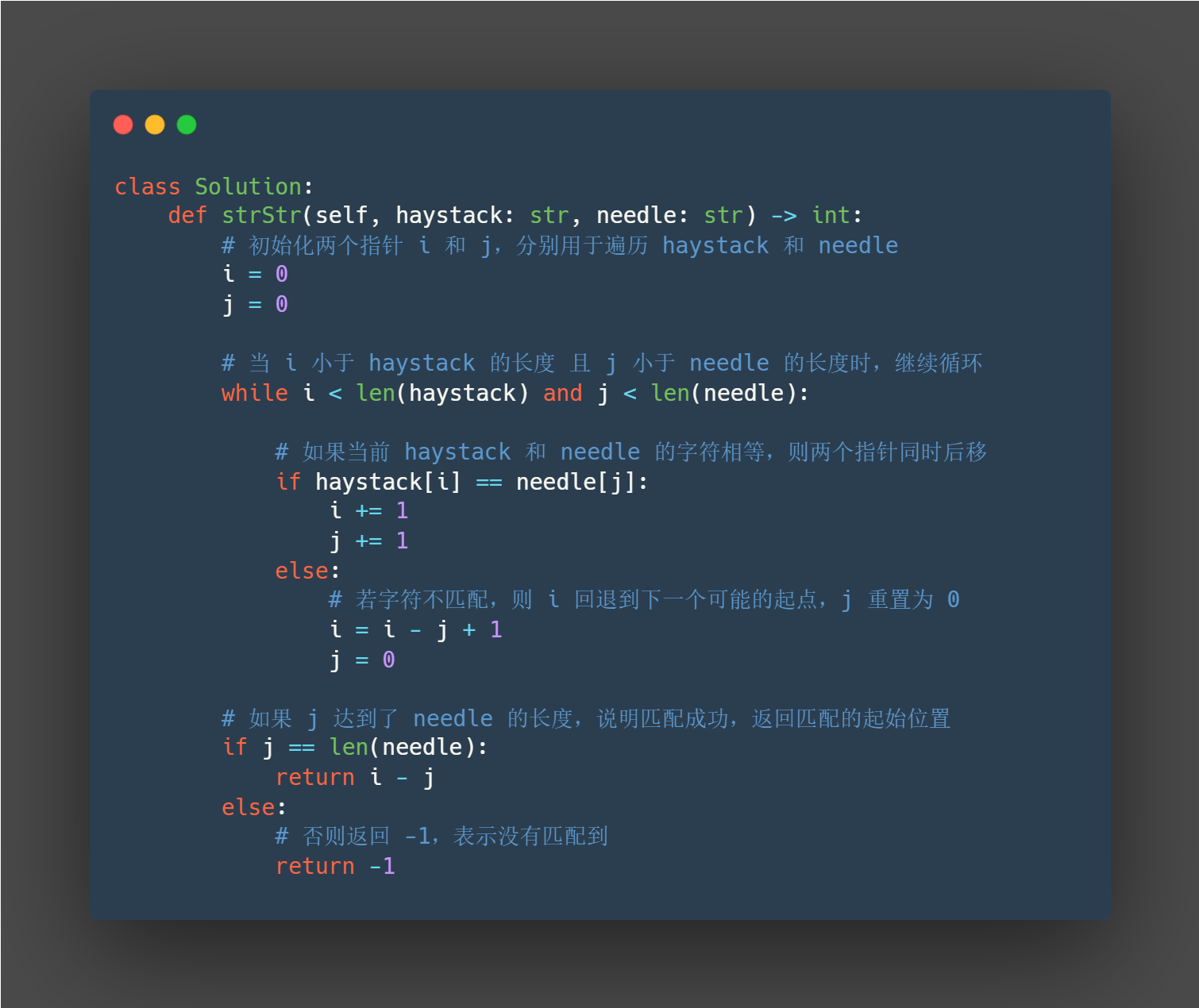
class Solution:
def strStr(self, haystack: str, needle: str) -> int:
# 初始化两个指针 i 和 j,分别用于遍历 haystack 和 needle
i = 0
j = 0
# 当 i 小于 haystack 的长度 且 j 小于 needle 的长度时,继续循环
while i < len(haystack) and j < len(needle):
# 如果当前 haystack 和 needle 的字符相等,则两个指针同时后移
if haystack[i] == needle[j]:
i += 1
j += 1
else:
# 若字符不匹配,则 i 回退到下一个可能的起点,j 重置为 0
i = i - j + 1
j = 0
# 如果 j 达到了 needle 的长度,说明匹配成功,返回匹配的起始位置
if j == len(needle):
return i - j
else:
# 否则返回 -1,表示没有匹配到
return -1
c++
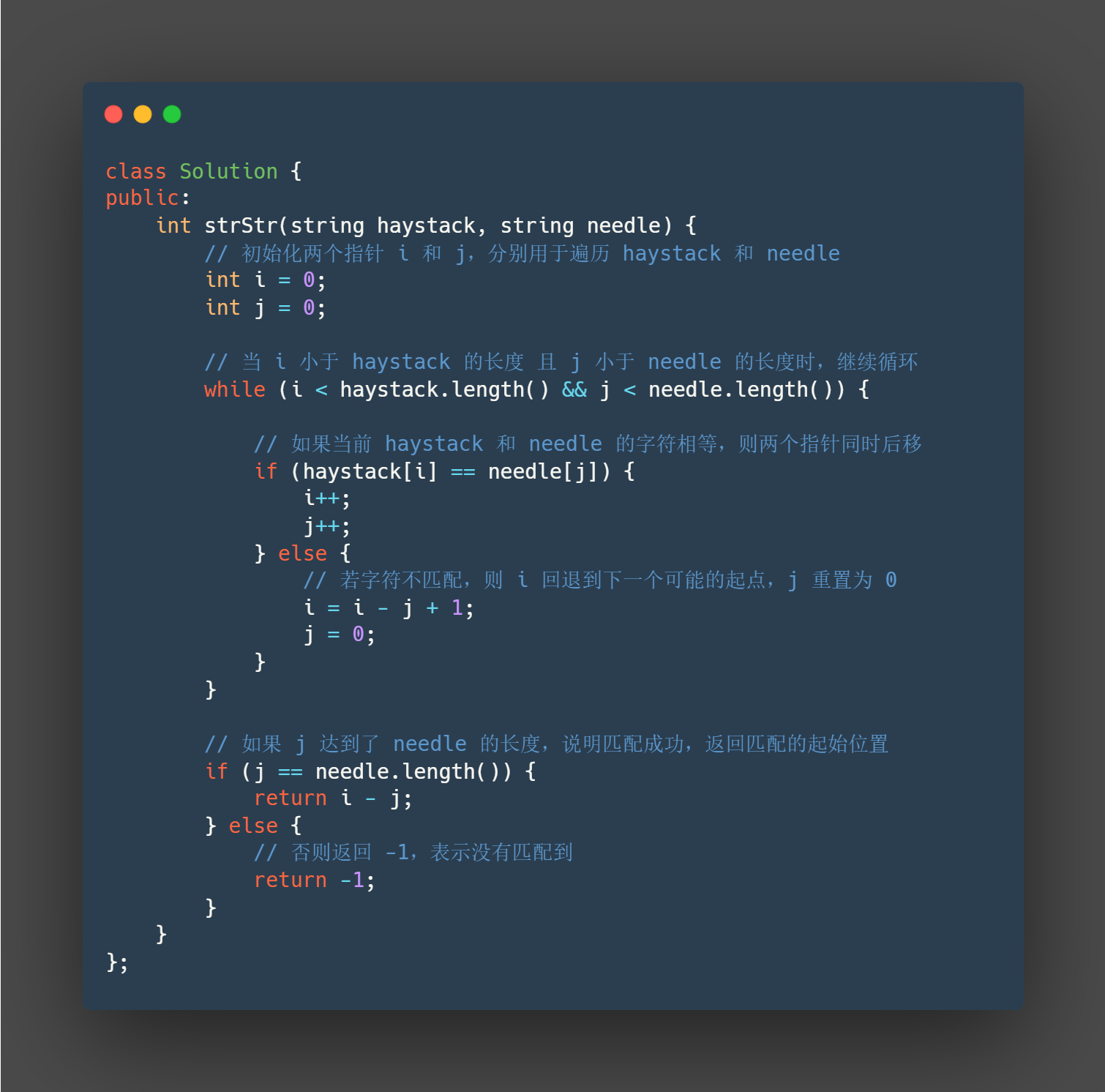
class Solution {
public:
int strStr(string haystack, string needle) {
// 初始化两个指针 i 和 j,分别用于遍历 haystack 和 needle
int i = 0;
int j = 0;
// 当 i 小于 haystack 的长度 且 j 小于 needle 的长度时,继续循环
while (i < haystack.length() && j < needle.length()) {
// 如果当前 haystack 和 needle 的字符相等,则两个指针同时后移
if (haystack[i] == needle[j]) {
i++;
j++;
} else {
// 若字符不匹配,则 i 回退到下一个可能的起点,j 重置为 0
i = i - j + 1;
j = 0;
}
}
// 如果 j 达到了 needle 的长度,说明匹配成功,返回匹配的起始位置
if (j == needle.length()) {
return i - j;
} else {
// 否则返回 -1,表示没有匹配到
return -1;
}
}
};
时间复杂度分析:
这段代码的核心是一个双指针遍历字符串的算法。我们可以分析两个指针的移动情况来确定时间复杂度。
- 指针
i的移动:i指向haystack,在每次循环中,i会根据字符匹配情况进行移动:- 如果字符匹配成功,
i会递增一次,继续匹配下一个字符。 - 如果字符不匹配,
i会回退到下一个可能的起始位置,然后继续尝试匹配。i回退的距离是j的长度(也就是目前已匹配的字符数),这部分操作的开销在最坏情况下也为 O(1) 的调整。
- 如果字符匹配成功,
- 指针
j的移动:j指向needle,它会不断递增直到needle完全匹配或者字符不匹配。每次匹配不成功时,j都会重置为 0,继续从头匹配。
在最坏的情况下,比如当 haystack 中的字符大部分与 needle 的前半部分相匹配而后半部分不匹配时,指针 i 可能会回退多次,但由于每次回退的总距离可以通过双指针逐步逼近,整个遍历过程中 i 的总移动次数不会超过 haystack.length(),即 O(n)。
因此,这种情况下,最坏的时间复杂度为:
- O(n * m),其中
n是haystack的长度,m是needle的长度。在最坏情况下,i可能需要逐个字符检查,并且每次都要重新从needle的开头开始匹配。
空间复杂度分析:
该算法只使用了几个额外的变量 i、j 和一些常量来跟踪当前位置,因此空间复杂度为 O(1)。
算法并不需要额外的存储空间来存储数组、表格或者递归栈空间等,仅仅依赖输入的两个字符串,因此它的空间复杂度是常数级别的。
- 空间复杂度:O(1)。
总结:
- 时间复杂度: O(n * m),其中
n是haystack的长度,m是needle的长度。 - 空间复杂度: O(1)。


评论区